程序中出现错误并对错误进行处理是很自然的现象,我们没有必要害怕程序出错,更重要的是我们要学会发现错误发生的原因、获取错误的信息以及处理错误的方法。在LabVIEW中,什么叫做错误呢?简单的说,一个函数或子VI不能够完成其所设定的功能就可以称为出错了。出错的原因可能是无法访问必要的资源或者是函数接受的参数是无效的等等。在LabVIEW这个数据流的编程语言中,是是使用错误簇这种数据类型来传递错误信息的。
错误簇(Error Cluster)数据类型
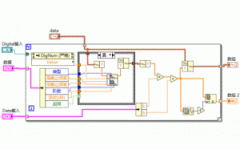
如下图所示,LabVIEW中的错误簇是由以下三部分组成的: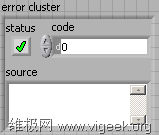
- status 状态布尔量,当有错误发生时该值为TRUE,没有错误发生时该值为FALSE;
- code 标识错误代码的32位整型变量,当该值为负时表示有程序警告,为零表示没出错,为正表示有错误发生;
- source 错误原因字符串,给出了出错原因的描述性信息。
错误信息传递:错误数据流
LabVIEW本身就是一个基于数据流的编程语言,对于错误信息的传递也是使用数据流的形式在LabVIEW的程序框图中实现的。如下图中的红点标识处所示,错误簇数据在框图中是按顺序、连续的在程序中传递的。
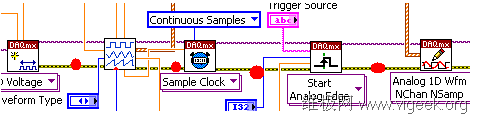
很多LabVIEW函数以及子VI都有错误输入(Error In)以及错误输出(Error Out)端点,一般这两个端点分别位于函数节点图标的左下侧以及右下侧。
在子VI中如何对错误做出反应
函数以及子VI对于错误的一般反应都是按照如下两点实现的:
- 如果错误输入(Error In)参数输入了一个错误,不要进行除了清理操作之外的任何其他操作,而清理操作包括了:关闭文件、关闭设备或通讯端口、将系统切换回空闲或安全状态(例如关闭电机等等);
- 如果在函数或子VI内部出错,就需要通过函数或子VI的错误输出(Error Out)端点将该错误信息传递出去。如果从函数或子VI的错误输入端点早就传入了一个错误信息,那就原封不动的将该错误信息从错误输出端点输出。
以错误簇为条件的Case结构
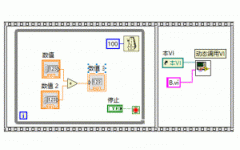
通过使用如下图所示的错误簇Case结构,我们可以轻易的实现上面中的第2条的常规错误处理动作。实现错误簇Case结构只需要将一个错误簇数据连接到Case结构的选择端上。
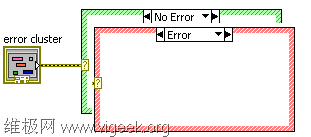
当错误簇数据连接到Case结构的选择端子后,Case结构的两个默认帧的名称就自动变为“No Error”和“Error”了。在程序运行时,如果输入的错误簇中没有出错信息,就会执行Case结构中的No Error帧中的代码,反之则执行Error帧中的代码。实现上面提到的第2条功能只需要将Error帧中错误簇直接连接到VI的错误输出端,将没错误的情况下的执行代码放到No Error帧中。
错误数据融合
在程序中如果上游的函数就已经出错了,这时要做清理工作该怎么办呢?这时就不便使用错误Case结构了,最好就是使用融合错误(Merge Error)函数将所有的上游错误融合在一起,如下图所示:
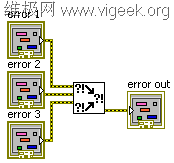
这个函数可以在Programming>>Dialog & User Interface面板中找到。在使用这个函数的时候要注意,错误簇只能包含一个错误信息,而这个融合错误的函数将多个错误融合为一个错误,最终得到的错误是按照该函数的输入端至上而下的优先级得到的,也就是说优先级最高的输入端上如果有错误数据,最终的输出就是该错误数据。在实际的编程中,就需要按照程序中实际需要连接这个函数的错误输入数据。如果所有的输入端都没有错误发生,最后该函数的输出也是无错误的(no error)。